
Routage asymétrique, flooding unicast et troubleshooting
On parle de routage asymétrique lorsqu’un paquet emprunte un chemin différent selon le sens du trafic. En d’autres termes, lorsqu’un paquet emprunte un chemin dans le sens Aller, et un autre chemin dans le sens du retour. Lorsque tout fonctionne correctement, vous pouvez ne pas vous rendre compte que du routage asymétrique est en cours sur votre réseau, mais c’est lorsque vous ajoutez du NAT ou des Firewalls à l’architecture que tout se complique, car ils commencent à dropper les flux. Je vais montrer dans cet article ce qu’est le routage asymétrique, comment le détecter et pourquoi il peut causer des problèmes dans une architecture Data Center par exemple.
Le routage asymétrique
Nous allons utiliser l’architecture suivante afin mieux comprendre:
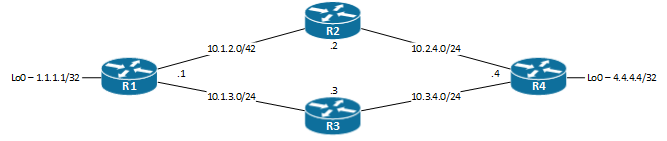
Détection du routage asymétrique
Afin de détecter facilement le routage asymétrique, on pourrait penser qu’un traceroute suffit. Cependant, le traceroute n’effectue que des requêtes ICMP dans un seul sens, avec des TTL différentes. L’outil idéal pour la détection de routage asymétrique est le ping étendu, avec l’option “Record route” activée.
Comme le dit la RFC
The record route option provides a means to record the route of an internet datagram.
When an internet module routes a datagram it checks to see if the record route option is present. If it is, it inserts its own internet address as known in the environment into which this datagram is being forwarded into the recorded route beginning at the byte indicated by the pointer, and increments the pointer by four.
If the route data area is already full (the pointer exceeds the length) the datagram is forwarded without inserting the address into the recorded route. If there is some room but not enough room for a full address to be inserted, the original datagram is considered to be in error and is discarded. In either case an ICMP parameter problem message may be sent to the source host.
Voici comment faire pour activer l’option “Record route” du paquet ICMP.
Je commence par faire un traceroute depuis la Loopback de R1 vers 4.4.4.4.
R1#traceroute Protocol [ip]: Target IP address: 4.4.4.4 Source address: 1.1.1.1 [....] Type escape sequence to abort. Tracing the route to 4.4.4.4 VRF info: (vrf in name/id, vrf out name/id) 1 10.1.3.3 0 msec 1 msec 0 msec 2 10.3.4.4 0 msec * 0 msec |
Le trafic passe bien par R3, puis R4 et revient ! Pas de routage asymétrique donc? Etant donnée que nous n’avons pas d’informations sur le retour des paquets, on ne peut pas encore l’affirmer. Pour en être sûr, il faut effectuer un ping avec l’option “record route” activée, comme ceci :
R1(config-line)#do ping Protocol [ip]: Target IP address: 4.4.4.4 Repeat count [5]: 1 Datagram size [100]: Timeout in seconds [2]: Extended commands [n]: y Source address or interface: 1.1.1.1 Type of service [0]: Set DF bit in IP header? [no]: Validate reply data? [no]: Data pattern [0xABCD]: Loose, Strict, Record, Timestamp, Verbose[none]: r Number of hops [ 9 ]: Loose, Strict, Record, Timestamp, Verbose[RV]: Sweep range of sizes [n]: Type escape sequence to abort. Sending 1, 100-byte ICMP Echos to 4.4.4.4, timeout is 2 seconds: Packet sent with a source address of 1.1.1.1 Packet has IP options: Total option bytes= 39, padded length=40 Record route: <*> (0.0.0.0) (0.0.0.0) (0.0.0.0) (0.0.0.0) (0.0.0.0) (0.0.0.0) (0.0.0.0) (0.0.0.0) (0.0.0.0) Reply to request 0 (1 ms). Received packet has options Total option bytes= 40, padded length=40 Record route: (10.1.3.1) (10.3.4.3) (4.4.4.4) (10.2.4.4) (10.1.2.2) (1.1.1.1) <*> (0.0.0.0) (0.0.0.0) (0.0.0.0) End of list Success rate is 100 percent (1/1), round-trip min/avg/max = 1/1/1 ms |
Nous pouvons voir qu’il y à bien du routage asymétrique, car les paquets passent de R1 (10.1.3.1) à R3 (10.3.4.3) à R4 (4.4.4.4) mais R4 envoi la réponse à R2 (10.1.2.2) et de retour vers R1 (10.1.1.1).
Voici un schéma du chemin emprunté par les paquets:
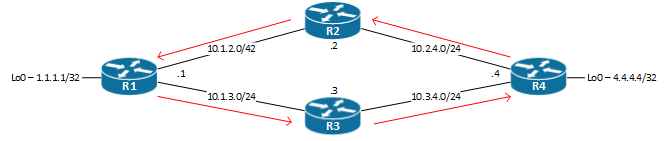
Avec ces informations, nous pouvons prendre les mesures appropriées pour palier à ce problème. Dans notre cas, il suffit de modifier la route sur R4, pour que ce routeur envoi les paquets destinés à 1.1.1.1 sur son interface 10.3.4.4.
R4(config)#no ip route 0.0.0.0 0.0.0.0 R4(config)#ip route 0.0.0.0 0.0.0.0 10.3.4.3 |
Et voici le résultat du ping avec le record route :
R1#ping Protocol [ip]: Target IP address: 4.4.4.4 Repeat count [5]: 1 Datagram size [100]: Timeout in seconds [2]: Extended commands [n]: y Source address or interface: 1.1.1.1 Type of service [0]: Set DF bit in IP header? [no]: Validate reply data? [no]: Data pattern [0xABCD]: Loose, Strict, Record, Timestamp, Verbose[none]: r Number of hops [ 9 ]: Loose, Strict, Record, Timestamp, Verbose[RV]: Sweep range of sizes [n]: Type escape sequence to abort. Sending 1, 100-byte ICMP Echos to 4.4.4.4, timeout is 2 seconds: Packet sent with a source address of 1.1.1.1 Packet has IP options: Total option bytes= 39, padded length=40 Record route: <*> (0.0.0.0) (0.0.0.0) (0.0.0.0) (0.0.0.0) (0.0.0.0) (0.0.0.0) (0.0.0.0) (0.0.0.0) (0.0.0.0) Reply to request 0 (2 ms). Received packet has options Total option bytes= 40, padded length=40 Record route: (10.1.3.1) (10.3.4.3) (4.4.4.4) (10.3.4.4) (10.1.3.3) (1.1.1.1) <*> (0.0.0.0) (0.0.0.0) (0.0.0.0) End of list Success rate is 100 percent (1/1), round-trip min/avg/max = 2/2/2 ms |
Plus de routage asymétrique, le paquet passent bien de R1 (10.1.3.1) à R3 (10.3.4.3), puis R4 (4.4.4.4), et R4 (10.3.4.4) renvoi le paquet à R3 (10.1.3.3) qui fait suivre à R1 (1.1.1.1).
Une commande à retenir donc car vous pourriez bien en avoir besoin dans un futur proche lorsque vos firewalls commenceront à droper des flux “sans raison” apparente, ou lors de votre exam CCIE pour déceler rapidement le problème.
Conséquences du routage asymétrique
Drop des paquets
Nous en avons parlé juste avant, les firewalls maintiennent une table de sessions pour les paquets. Lorsqu’un paquet arrive sur le Firewall depuis une zone de sécurité vers une autre zone de sécurité, il est enregistré. Le firewall attends alors le paquet retour. En cas de routage asymétrique, le firewall peut voire le paquet arriver, mais le paquet repart sur un autre firewall lors de son retour, ce deuxième firewall dropera alors le flux, car il n’aura pas enregistré le paquet initial.
Voici un schéma pour illustrer ce scénario plus simplement :
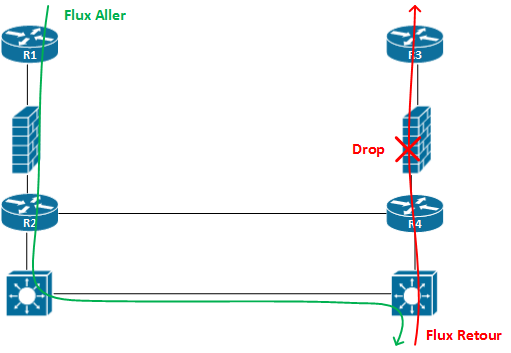
Afin de palier à ce problème, il peut être possible de partager les tables de sessions des firewalls, mais c’est rarement possible lorsque les firewalls sont physiquement positionnés dans des Data Center différents.
Flooding Unicast
Le routage Asymétrique à également des conséquences lorsqu’il apparait sur des Switch sachant faire du niveau 3. L’asymétrie peut alors entrainer du Flooding unicast, lorsque l’adresse MAC du paquet n’est pas présente dans la table de Forwarding du switch.
Pour comprendre cela, il faut se remettre en tête que les switch L3 ont 3 tables:
Table ARP – Elle mappe une adresse IP à une adresse MAC pour fournir la communication niveau 2, dans un même domaine de broadcast.
Table CAM – Une trame arrive sur un port du switch, l’adresse MAC source est alors apprise et enregistrée dans la table CAM, avec son numéro de Vlan et un timestamp. Si une entrée était déjà présente pour la même MAC avec un port différent, alors l’entrée précédente est supprimée. Si l’entrée était déjà présente mais sur le même port, et le même Vlan, alors le timestamp est mis à jour.
TCAM (Ternary Content Addressable Memory) – Cette table n’est pas utile pour comprendre le fonctionnement du flooding unicast mais le switch L3 l’utilise pour y stocker sa table de routage. La plupart des switchs ont même plusieurs TCAM.
Important : sur les switchs L3, le timeout par défaut pour les entrées de la table ARP (ARP table aging time) est de 4 heures, alors que la CAM expire au bout de 5 minutes (300 secondes).
Pour mettre en lumière le flooding unicast, nous allons utiliser l’architecture suivante:
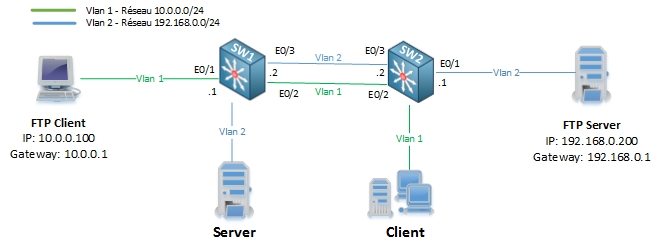
Nous avons un client FTP qui souhaite télécharger un fichier situé sur un serveur FTP. Le client à l’adresse IP 10.0.0.100 et est connecté au SW1 qui est sa passerelle par défaut pour le Vlan 1 (10.0.0.1). De l’autre coté, le serveur FTP (192.168.0.200) est connecté au SW2 qui est sa passerelle par défaut pour le Vlan 2 (192.168.0.1).
D’autres clients sont connectés au SW2 sur le Vlan 1 et un serveur est connecté dans le Vlan 2 sur SW1.
Supposons que le client FTP soit déjà connecté au serveur FTP, les tables CAM et ARP des switchs L3 contiennent les informations MAC/IP du client et du serveur. Mais que se passe-t’il lorsque le client FTP souhaite télécharger un gros fichier ?
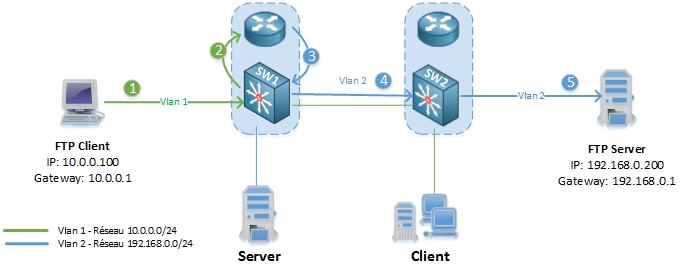
1. Le client FTP envoi une requête FTP à sa passerelle par défaut (SW1 – 10.0.0.1)
2-3. SW1 vérifie l’adresse de destination (192.168.0.200) dans la table de routage et transmet le paquet a l’interface Vlan 2.
4-5. SW1 transmet le paquet à SW2 qui transmet la requête FTP au serveur FTP.
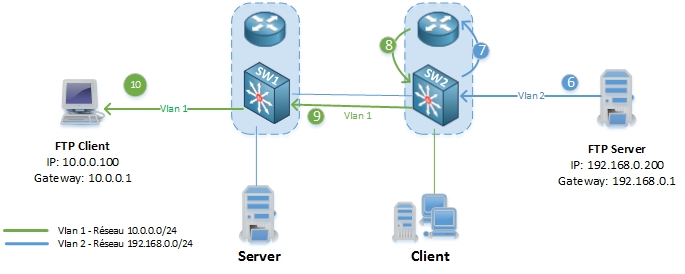
6. Le serveur FTP commence à envoyer le fichier (demandé par le client) à sa passerelle par défaut (SW2).
7-8. SW2 vérifie l’adresse de destination (10.0.0.100) dans sa table de routage et transmet le paquet a son interface Vlan 2.
9-10. SW2 transmet le paquet à SW1 qui transmet au client FTP.
Important: Après 5 minutes, les deux switchs L3 suppriment les adresses MAC des clients et serveurs FTP de leurs table CAM. Que se passe-t’il alors lorsque la table d’adresse MAC expire et que le client FTP souhaite télécharger d’autres fichiers ?
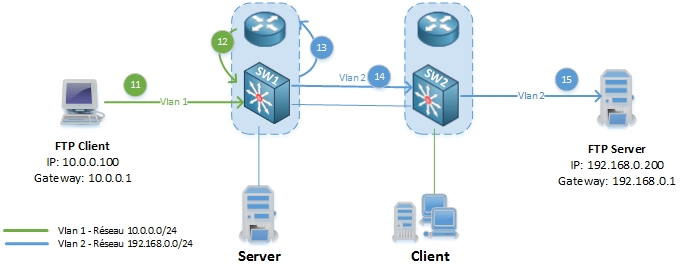
11. Le client FTP envoi la requête FTP à sa passerelle par défaut (SW1 – 10.0.0.1).
12-13-14. SW1 vérifie l’adresse de destination (192.168.0.200) dans sa table de routage et transmet le paquet à l’interface Vlan 2, mais la CAM ne trouve pas l’adresse MAC du serveur FTP, donc le SW1 floode les paquets à tous le Vlan 2 (le serveur connecté sur SW1 reçoit le paquet également) !
15. SW2 reçoit aussi le paquet et transmet aussi la requête FTP au serveur FTP.
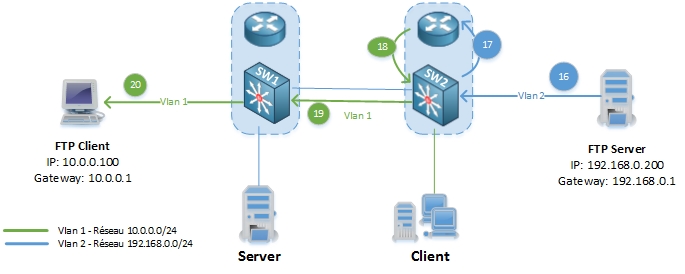
16. Le serveur FTP commence à envoyer les fichiers à sa passerelle par défaut(SW2 – 192.168.0.1).
17-18-19. SW2 vérifie l’adresse de destination (10.0.0.100) dans sa table de routage et transmet le paquet a l’interface Vlan 1, mais la CAM ne possède pas d’entrée pour l’adresse MAC du client FTP donc SW2 va flooder le paquet sur toutes les interfaces connectées au Vlan 1 (et donc au client connecté dans le Vlan 1 sur SW2).
20. SW1 reçoit également le flood et délivre le paquet au client FTP.
En résulte que les paquets du transfert entre client et serveur FTP sont floodés sur l’interface Vlan 1 de SW2 et Vlan 2 de SW1. Ce qui signifie que chaque port connecté au Vlan 1 sur SW2 et Vlan 2 sur SW1 va recevoir tous les paquets de la conversation entre 10.0.0.100 et 192.168.0.200. Cela cause un gros problème de connectivité pour les hôtes qui perçoivent toujours par un ralentissement du trafic.
Ce flooding est due au routage asymétrique et ne peut stopper que lorsque la table ARP expire ou que le switch envoi un paquet broadcast (ARP Request).
Que se passe-t’il si les entrées de la table ARP expirent ?
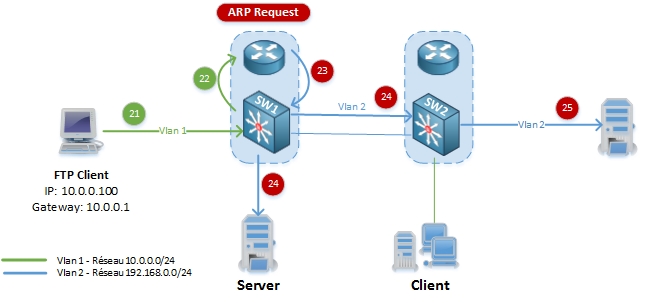
21. Le client FTP demande de télécharger le fichier du serveur FTP et l’envoi à sa passerelle par défaut (SW1 – 10.0.0.1).
22-23-24. SW1 vérifie l’adresse de destination (192.168.0.200) dans la table de routage, et vois qu’il n’y a pas d’entrée ARP pour 192.168.0.200, le Switch envoie alors une requête ARP (en broadcast sur le Vlan 2) qui demande “Qui à l’adresse IP 192.168.0.200 ?”
25. Le serveur FTP reçoit la requête ARP.
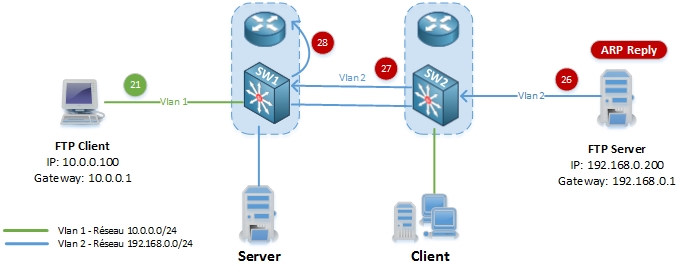
26-27. Le serveur FTP répond en envoyant un ARP Reply à SW2 qui transmet à SW1.
28. SW1 met à jour ses tables ARP et CAM, et le flooding unicast sur le Vlan 2 s’arrête, le paquet du client FTP est envoyé au serveur FTP (étapes 3-4-5).
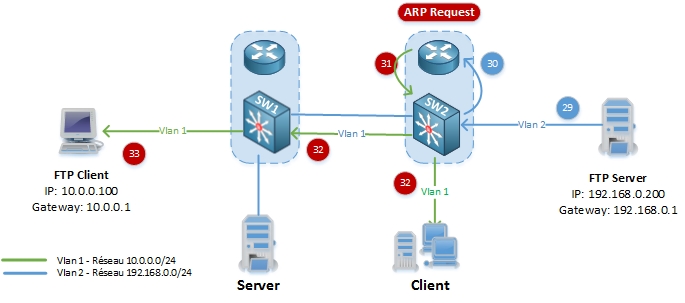
29. Le serveur FTP commence à envoyer le fichier au client FTP en utilisant sa passerelle par défaut (SW2 – 192.168.0.1).
30-31-32. Le SW2 vérifie l’adresse de destination (10.0.0.100) dans la table de routage, se rend compte qu’il n’y à pas d’entrée ARP pour 10.0.0.100, et donc le Switch L3 envoie une requête ARP (message broadcast sur le Vlan 1) pour demander “Qui à l’adresse IP 10.0.0.100 ?”?
33. Le client FTP reçoit le paquet ARP request.
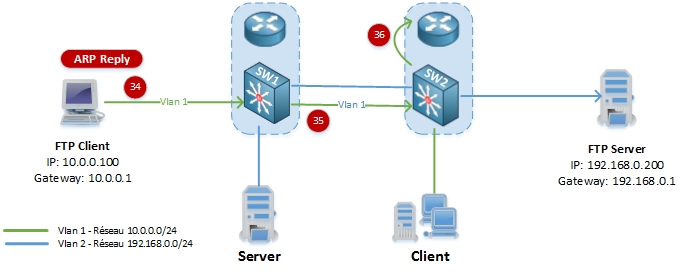
34-35. Le client FTP envoi un ARP Reply à SW1 qui transmet à SW2.
36. SW2 met à jour les tables ARP et CAM, et le flooding unicast s’arrête sur le Vlan 1 et le paquet du serveur FTP est renvoyé au client (comme aux étapes 8-9-10).
Comment limiter l’Unicast flooding ?
Il y à différentes approches pour limiter le flooding unicast due au routage asymétrique.
– Le mieux à faire : Supprimer le routage asymétrique.
– Une autre solution simple mais qui n’est en fin de compte qu’une solution de contournement: faire correspondre les timeout des tables ARP et CAM pour limiter la durée du flooding. Pendant l’unicast flooding, les paquets sont envoyés en broadcast, et pour éviter cela, il faut que l’apprentissage (CAM) se refasse avant que la table de L2 Forwarding (ARP) n’expire.
– Une autre solution de contournement serait de limiter le broadcast (avec la commande storm-control braodcast level x pps).
– Implémenter le protocole HSRP/VRRP, mais surtout en prenant soin de définir les routeurs HSRP/VRRP Actifs sur les mêmes passerelles.
Utiliser HSRP pour limiter le flooding unicast
Dans ce cas SW1 est le routeur actif et SW2 est le router en standby.
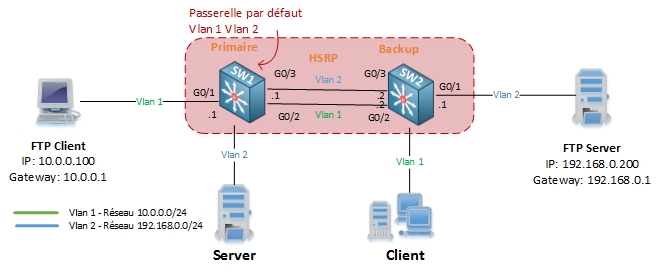
Dans cette configuration, SW1 agit en tant que routeur et Switch alors que SW2 n’agit que comme un Switch. Les paquets envoyés et reçus par le client FTP vont utiliser le même chemin (1-2-3-4-5 et 6-7-8-9-10)
car il n’y a pas de routage asymétrique. Pendant le transfert de fichier, la table d’adresse MAC (CAM) ne peut pas expirer car elle est constamment mise à jour. Pour cette raison, le flooding unicast n’a pas lieu.
Comment détecter du flooding unicast dans une capture Wireshark ?
Afin de détecter le flooding unicast, il est possible d’utiliser le logiciel Wireshark avec n’importe quel PC muni d’une carte réseau. Pour cela, connectez votre PC au port d’un Switch sur lequel vous suspectez le flooding unicast, et configurez votre Switch en mode Trunk, vous récupérerez ensuite le “bruit de fond” envoyé en broadcast via Wireshark.
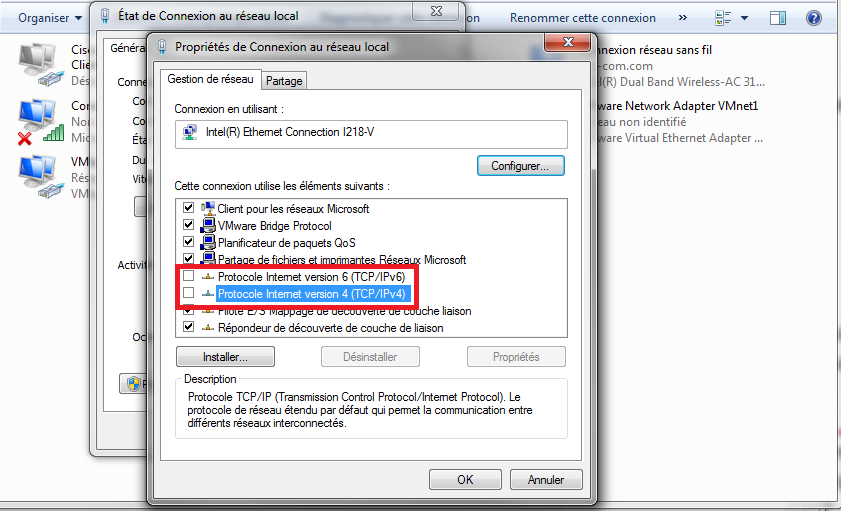
Afin de ne pas perturber la capture avec votre propre PC, vous pouvez désactiver les piles IPv4 et IPv6 de votre carte réseau comme ceci :
Afin de capturer le bruit de fond, il est nécessaire de:
– Connecter la sonde et le switch avec un câble droit,
– Configurer le port du switch en mode trunk, contenant tous les VLANs du switch.
Configuration du Switch:
Entrez en mode de configuration :
switch# configuration terminal |
Sélectionnez l’interface qui est relié au switch :
switch(config)# interface Fa 1/0 |
Configurez le mode trunk sur cette interface :
switch(config-if)# switchport mode trunk |
Configurez le mode trunk afin que tous les VLANs configurés sur l’équipement soient propagés sur ce port :
switch(config-if)# switchport trunk allowed vlan all |
Une fois le Switch configuré, et le câble branché, passons à la configuration de Wireshark:
– Lancez Wireshark
– Cliquez sur Capture > Interfaces
– Sélectionnez votre interface réseau puis cliquez sur Start
– Attendez quelques minutes, au minimum 10 minutes puis stoppez la capture.
Une fois la capture effectuée, vous pouvez vous rendre dans l’onglet “Statistiques” et cliquer sur “IO Graph”.
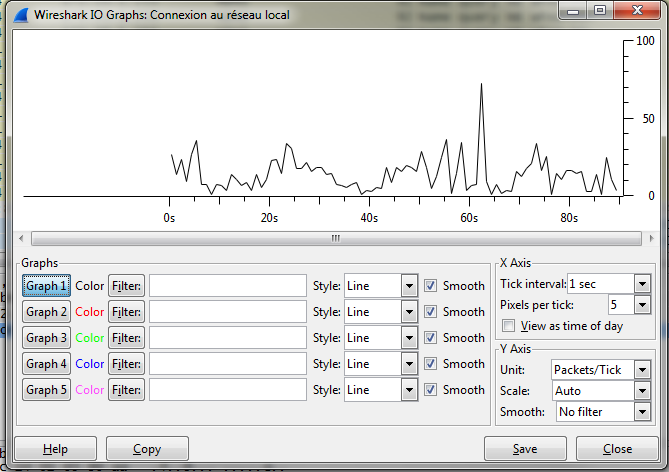
Vous pourrez alors filtrer les Vlans qui vous intéressent et détecter les pics de paquets qui pourraient être causés par de l’unicast flooding. Dans mon exemple je n’ai pas pu avoir une capture ayant ce problème d’unicast flooding, les valeures sont donc normales. Une valeure supérieure à 150pps/Vlan serait suspecte.
Sources :
- Initial Draft – Troubleshooting Asymmetrical Routing
- Ciscozine – Unicast flooding due to asymmetric routing
Benoit
Network engineer at CNS Communications. CCIE #47705, focused on R&S, Data Center, SD-WAN & Automation.
Follow Me:

Bravo pour cet exvellent article. Merci pour toutes ces infos.
Merci pour cette présentation. Le sujet est compliqué et bien expliqué.
un grand merci pour ces explications